






Product
Get Started with BioContainers using Rafay
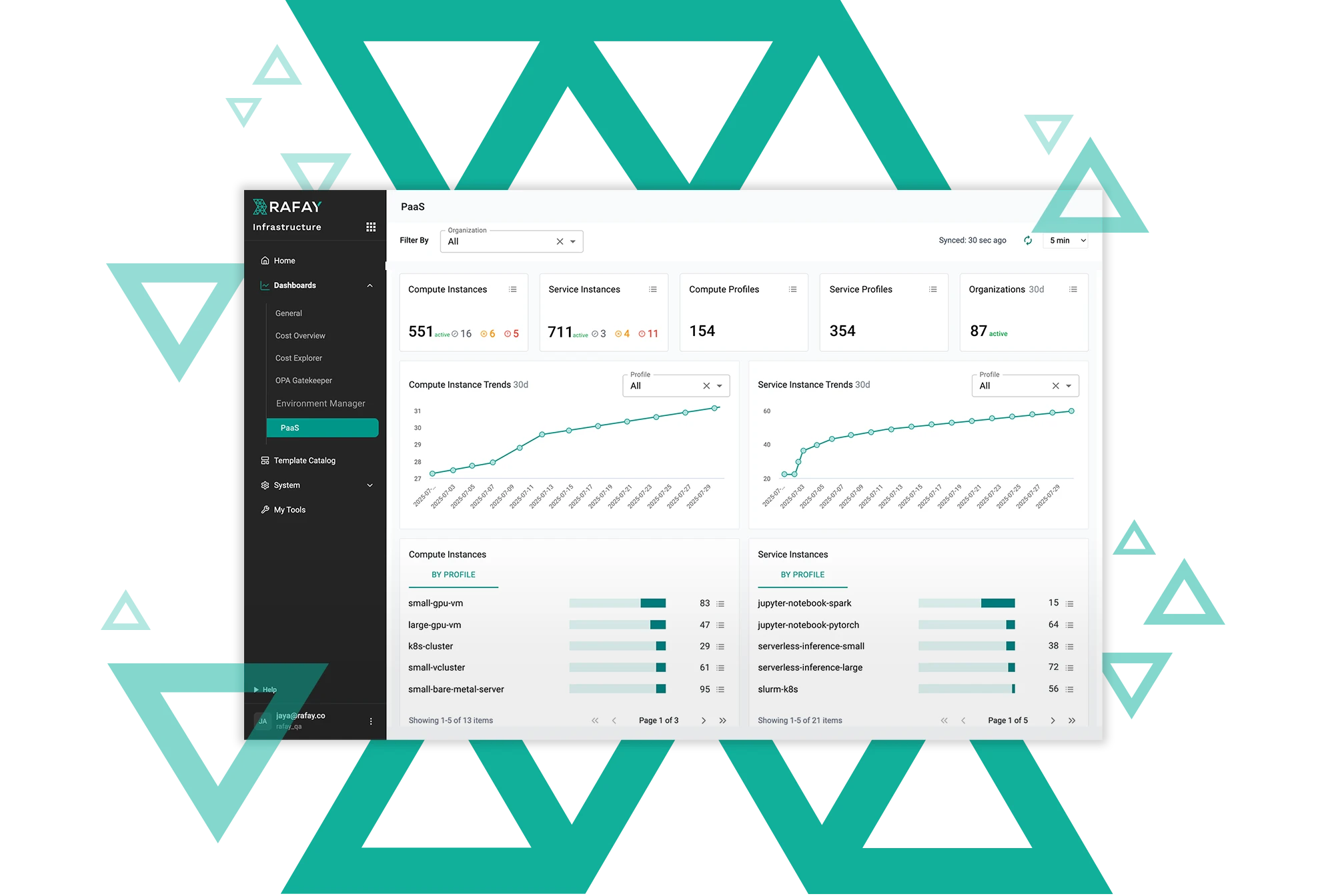
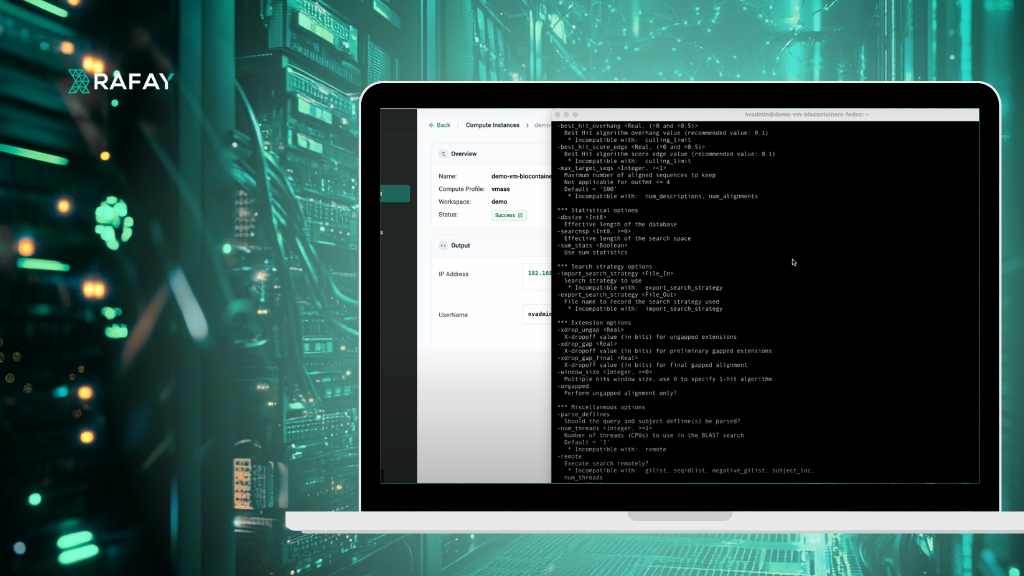
In this step-by-step guide, the Bioinformatics data scientist will use Rafay’s end user portal to launch a well resourced remote VM and run a series of BioContainers with Docker.
read More
No items found.
2025-06-10




